I've been using Perplexity for some time, and inspired by Simon Willison's post on his experience with GPT 5, I'm going to share what I've noticed about using Perplexity as a power user who has used it for almost 2 years now.
Tricks:
Some tricks that I've found useful for Perplexity:
-
Perplexity used to push replacing Google with Perplexity but I don’t think it’s gotten there yet. I've instead created a search alias for Perplexity where I can type in
p + tabto trigger Perplexity query.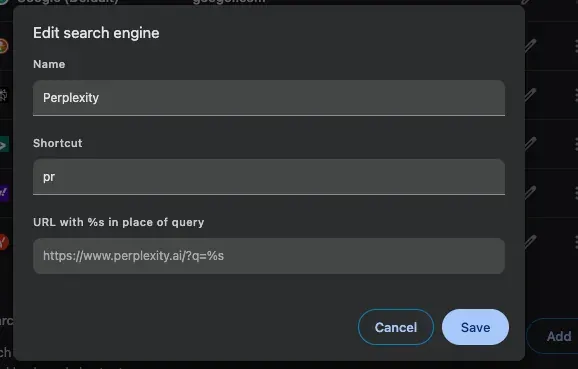
-
Personalization is useful for describing to the model what you're doing - especially for when I'm pasting in bash commands to debug something I just ran
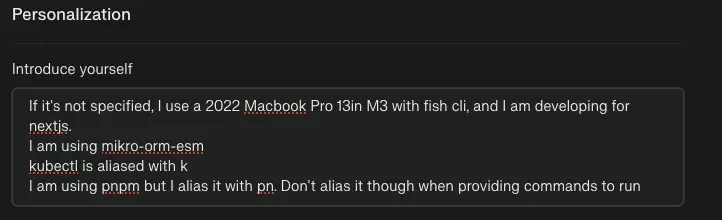
-
Auto mode is quite good!
One of the biggest discussion points for people in AI has been model quality in the auto mode.
The AI companies want to use cheaper models for requests, and ideally have their own models running so that can have higher margins. On paper, they say they can have better routing for specific requests, but with the incentive to cheap out to increase margins it's clear what they're doing.
It's been a problem for Cursor, where their "auto" mode seems to only use GPT 4.1, and none of the expensive models that are much more intelligent at coding – which has led a lot of power users to turn off the auto mode.
That said, Perplexity auto mode has been alright - you probably wouldn't notice if you were a new user. Their auto mode also seems to never route - it's just a wrapper for their Pro Search model, which is both genius and misleading.
When you open up the model picker for a query - you can't even select "Pro Search" on here!
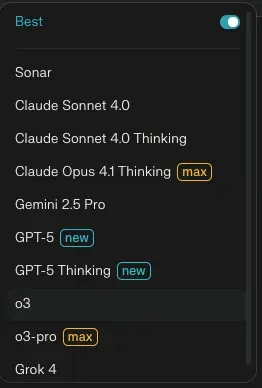
(I could be wrong here, where Pro Search isn't a model but an umbrella term, and it's actually one of the models on this list)
I suspect they throttle the queries/they're doing some batching to optimize the costs on these models as well. When I was daily driving Sonnet 4.0, the time to first token was really slow, and so was the speed of the generation - especially compared to Sonar, their home grown model.
That said, given the search usecase, I think it's more than fine to use a weaker model - given that the primary job with search is summarization and light analysis, rather than being 140 IQ at solving abstract problems that a task like coding demands.
To this end, the model has a heavy reliance on toolcalling. Even if you were to ask what 1+1 is, or something that's almost certainly in the corpus, it will do search.
The only time it won't do a search is in a followup if it feels that the query could be answered from the previous parts of the conversation (i.e. you're trying to summarize a specific point).
My queries:
Q: How are dogs named
I was looking at a dog adoption website and saw a bunch of interesting names for dogs, so I was curious on why this was the case.
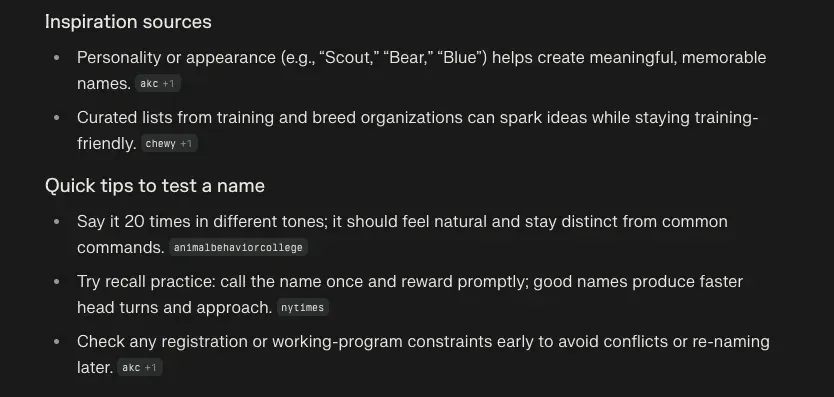
There's some interesting behavior showing up here - where the answer has a bunch of inline citations here that might or might not match up, but gives a trustworthy air to the answer.
The citations are very hit or miss
- the Animal Behavior college link doesn't even mention the point about saying the dog name 20 times, despite being cited there
- on the last point about checking registration or working programs, two sources are cited - the American Kennel Club (AKC) and a Seeing Eye dog organization - only the AKC link is relevant to that point
The answer overall was pretty good so I'm nitpicking, but in other cases where it's more ambiguous, the miscitations can be much more troublesome.
Q: Is 250 a fair price for a used lg ultrafine 5k
I was doing some shopping on Facebook marketplace, and saw a pretty good deal spring up, so I did some quick research.
I think the answer was ok – it wasn't searching Ebay for some reason though, which is what I would do if I was searching for this myself. I did the same query, adding Ebay to the end, and it did end up searching, but it was interesting that it didn't do it the first time around.
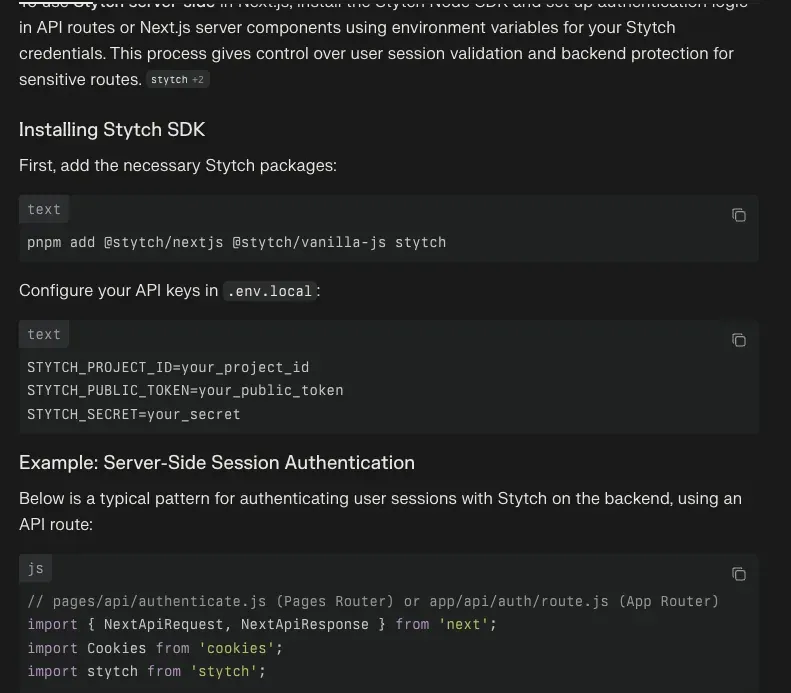
Q: How do i use stytch serverside nextjs
I was doing an integration of Stytch for a project I was working on, and I've found that it's really nice to use Perplexity to go through dev docs/github repos for code examples.
In contrast, even though Cursor has some search abilities, they seem really poor at gathering information retrieval, so I've resorted to just copy and pasting this into the prompt when I need to search things up.
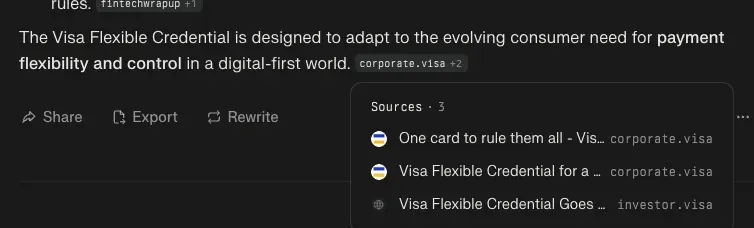
Q: What is visa flexible credential
I was reading a fintech newsletter on Klarna, and was interested by a mention of this.
It was a pretty good answer, but this last part gave me some pause - it's not super neutral language, and yup - the it was lifting straight from a corporate marketing website.
This is one area that Auto Mode's weaker model does bite - if it's summarizing low quality info (i.e. company press releases) for a response, it doesn't have any analysis on the underlying content. In other words, it's very susceptible to the Garbage in, Garbage out problem - which can be especially bad if you phrase your query poorly.
I reran the query with the rewrite feature with GPT5 and the answer that came out was more neutral in tone.
Overall:
There's some things that could be improved about how Perplexity handles search, but it's very good overall. I think the UI is really nice and they've clearly though through the UX.
I'm down to try other solutions, but I'll probably keep Perplexity around for now.